Fictional scenario: a turn in the right direction...A car rental company has recently deployed a new AI-based chatbot for customer support service. After several years in business, it became clear that effective 24/7 customer support was critical to the success of the business, as customers often contacted the company outside of office hours with issues that required an immediate response (e.g. how to report an accident or requests for roadside assistance).
Previously, telephone operators handled these requests, but during periods of high demand, such as the summer and Christmas holidays, there were often complaints about long waiting queues for operators to respond. This led the company to test an off-the-shelf chatbot system that proved to be only marginally better than the previous setup: the chatbot responses lacked insight on the business particularities and most times the chatbot directed the call to an operator.
Eventually, the company moved to another AI-based chatbot solution. The model was trained using documents collected during the company's operations over the years. This included information from previous customer incidents involving rental cars (such as accident reports and documents required by local authorities when crossing borders) and the corresponding steps the company took to resolve them, as well as previous customer complaints and frequently asked questions.
The new system allowed customers to ask questions and follow-up on the answers they were given to get more details on the issues at hand. By having access to a current list of partners (such as towing, car repair and legal services), they were able to provide customers in need with accurate contact details and opening hours.
Two months after deploying the new system the company made a survey among its customers and identified an overall increase in the client satisfaction. In general, customers reported that they had been able to get a solution when interacting with the chatbot system, with a decrease in the number of times the chatbot had to handover the customer to an operator. ... and a turn for the worstThe company’s quality and compliance team reviewed a sample of customer interactions with the AI-based chatbot a few weeks after the system was deployed to ensure it was working as expected.
At first, nothing seemed out of the ordinary, except for the occasional situation where the system was unable to identify a specific answer to a customer's query, resulting in the call being transferred to an operator.
Eventually, however, the team noticed some strange patterns in the questions asked by one of the company's clients. What began as a few questions about how the firm handled road accidents in the south of France in the past eventually evolved into a series of very specific questions about how the firm handled road accidents that occurred in a particular month in Agde, a town on the south coast of France.
The chatbot's interlocutor was particularly interested to know what kind of information the company would store from police accident reports. Much to the team's surprise, the system revealed that a positive driving under the influence (DUI) had been recorded in a police accident report during that time.
This incident was immediately reported to the company management, which confirmed that the information provided by the chatbot originated from the company’s customer management database. In fact, a traffic accident had been reported to the police authorities in Agde during that period and had even made the local news because of the dramatic nature of the accident, from which fortunately all those involved had emerged unharmed. Now there was a high chance that the information provided by the chatbot could be traced back to the identity of those individuals. |
Retrieval-augmented generation (RAG)
By Vítor Bernardo
Recent advances in large language models (LLMs) have significantly improved their size. However, LLMs' responses are typically shaped or limited by the data they were trained on[i]. This can lead to inaccuracies or outdated information on the outputs, particularly when dealing with factual queries or tasks requiring specific domain knowledge. The very way the LLMs work also leads to so-called ‘hallucinations’[ii].
Retrieval-augmented generation (RAG) is a technique that overcomes these limitations by acting as a personal library assistant for LLMs, giving them access to external knowledge bases to supplement their internal knowledge.
At its core, RAG consists of two main components: a retriever[iii] and a generator[iv]. The retriever searches a large database of documents or knowledge sources - this could include structured data from organisational databases and unstructured data (such as documents, web pages, images, or videos) to find relevant information based on an input query. It identifies and ranks the most relevant pieces of text that can help generate a more accurate and informed response.
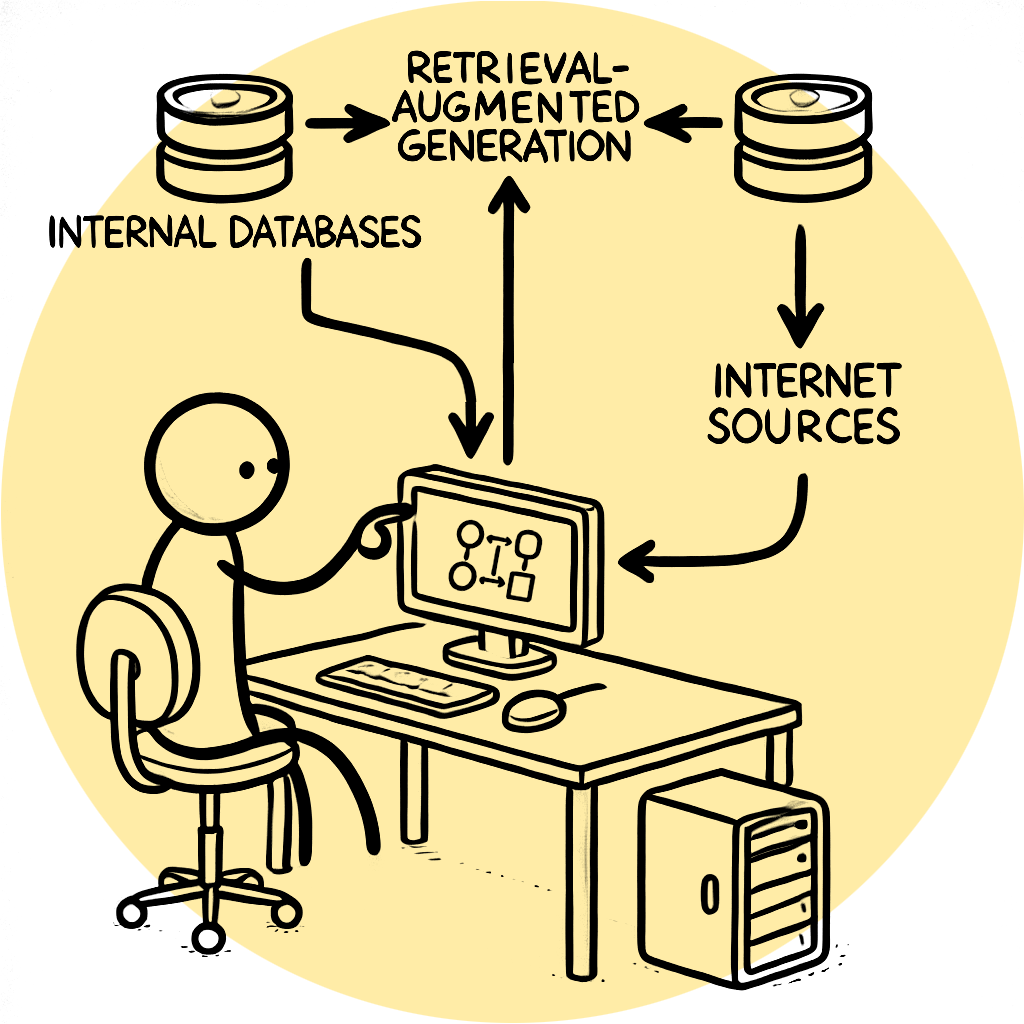
Once the retriever identifies relevant text, the generator, typically a transformer-based[v] model uses this information to produce a coherent and contextually appropriate response. The generator is fine-tuned to integrate the retrieved data seamlessly, ensuring that the final output is not only grammatically correct but also enriched with factual content from the retrieved documents.
RAG models can also generate content in formats other than text, such as images, video and source code.
![]() One advantage of RAG models over traditional LLMs is their improved factual accuracy, especially when dealing with rapidly changing information.
One advantage of RAG models over traditional LLMs is their improved factual accuracy, especially when dealing with rapidly changing information.
Moreover, RAG allows LLMs to specialise in specific domains. By providing them with relevant domain-specific documents or research papers, these models can offer specialised, domain-specific answers.
For instance, in education they can provide students with accurate explanations and additional context from textbooks and academic articles. In the legal and medical fields, they can assist professionals by retrieving relevant case law or medical literature to support decision-making. In customer support, RAG models can retrieve the latest troubleshooting steps from a knowledge base, providing users with up-to-date and accurate solutions.
RAG models also reduce - but do not completely eliminate - the risk of hallucinations often associated with generative models[vi] by grounding the generation process in retrieved, verifiable documents. In fact, “for an LLM using RAG to come up with a good answer, it has to both retrieve the information correctly and generate the response correctly. A bad answer results when one or both parts of the process fail”.[1]
Furthermore, implementing RAG models comes with challenges. Efficient retrieval from large databases requires fine-tuned indexing and search algorithms to maintain speed and accuracy. Additionally, ensuring the seamless integration of retrieved content into the generative process requires careful adjustment of the generator model to handle diverse and potentially unstructured data from the retriever. Selecting the most relevant documents also requires refinement of information retrieval techniques to avoid overwhelming the LLM with irrelevant details.
By leveraging databases and sophisticated retrieval mechanisms, RAG models address the limitations of generative systems, offering a promising solution for applications requiring precise and up-to-date information.
Development status
Currently, RAG is rapidly transitioning from theory to practice, becoming a quickly developing reality. It has already expanded beyond text-based responses, moving into a wider range of data formats. This expansion has led to the development of innovative models that integrate RAG concepts across different domains, including image generation and captioning, audio and video (e.g. converting machine-translated data into speech), and source code generation, summarization and completion.
RAG is actively being researched and developed with proofs of concept and experimental models being tested and some early commercial applications of RAG are already in the market, especially in areas like enhanced customer support, domain-specific assistance (e.g., legal, medical), and more intelligent chatbots.
RAG has also emerged as a promising tool for interdisciplinary applications such as molecular generation, medical tasks and computational research.
Future RAG technology development is likely to focus on three key areas.
The first is the improvement of the retrieval mechanisms to be able to handle more nuanced and contextual searches. This will improve the quality of information retrieved. This involves both improving the dataset quality used for retrieval and refining retrieval techniques to prioritize the most relevant and high-quality information from the datasets.
Second, the integration of multimodal data, such as combining text with images or other forms of data can extend the applicability of RAG models across different domains.
Finally, advances in fine-tuning and personalisation will enable RAG models to better adapt to individual user preferences and domain-specific requirements.
While existing RAG models can significantly improve LLM performance in various domains, they often require complex pre-training and fine-tuning processes. This significantly increases the time and storage overhead, reducing the scalability of RAG models.
We can also expect to see greater demand for integration with real-time data, enabling up-to-the-minute information retrieval. This can be particularly useful in areas where developments are very dynamic, such as finance and news.
Potential impact on individuals
The ability of RAG systems to specialise in specific areas based on curated information from within organisations suggests that the results will be factually accurate. In contexts where the quality of these systems' decisions could affect individuals, improved accuracy could reduce negative outcomes. For example, a virtual assistant for an online retailer could combine internal knowledge bases to generate accurate, contextually relevant responses to customer queries.
However, when RAG systems retrieve information from external sources, such as websites whose accuracy and timeliness cannot be guaranteed, results may be inaccurate. It has already been demonstrated[2] that misleading text and instructions can be included in hidden content on web pages, causing LLMs to take these instructions into account - an attack known as indirect prompt injection.
Decisions supported by such systems could lead to poor outcomes, potentially harming individuals. For example, if a law firm uses RAG system to assist lawyers by retrieving case law, statutes and precedents, the retrieval of outdated or incorrect precedents could result in legal advice that suggests a less stringent strategy than is necessary.
In addition, certain user queries could be specific enough to cause RAG systems to retrieve and disclose personal data that was inadvertently included in the model training. Such disclosure would constitute a breach of personal data.
This issue requires careful consideration. Given that RAG systems may query data repositories containing sensitive information, there is a risk that unauthorised users may attempt to trick the systems into revealing confidential, possibly personal, information in the responses. The system could produce responses that are so descriptive that an attacker could infer the identity of the individual even without direct identifiers.
In this sense, RAG should be seen as a mechanism that allows users to retrieve information from systems where access is normally restricted, and where sensitive data could be inadvertently exposed, whether by accident or deliberate action. Therefore, careful model alignment is essential.
Another consideration is the need for RAG systems to integrate with multiple data sources. Databases, customer services and other data sources need to be accessible and searchable by RAG systems, requiring greater efforts to ensure the security, confidentiality and integrity of the data for which organisations are responsible. At the same time, also in this context, the processing of personal data must comply in particular with the key data protection requirements of necessity and proportionality.
In scenarios where organisations rely on outsourced RAG models that involve the transfer and processing of personal data by external parties, maintaining the confidentiality of personal data and complying with the data transfer conditions set out in Chapter V (Transfers of personal data to third countries or international organisations) of the GDPR may be particularly challenging.
Suggestions for further reading
- Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., ... & Wang, H. (2023). Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997.https://arxiv.org/pdf/2312.10997
- Hu, Y., & Lu, Y. (2024). RAG and RAU: A survey on retrieval-augmented language model in natural language processing. arXiv preprint arXiv:2404.19543.https://arxiv.org/pdf/2404.19543?trk=public_post_comment-text
- Jiang, Z., Xu, F. F., Gao, L., Sun, Z., Liu, Q., Dwivedi-Yu, J., ... & Neubig, G. (2023). Active retrieval augmented generation. arXiv preprint arXiv:2305.06983.https://arxiv.org/pdf/2305.06983
- Zhao, P., Zhang, H., Yu, Q., Wang, Z., Geng, Y., Fu, F., ... & Cui, B. (2024). Retrieval-augmented generation for AI-generated content: A survey. arXiv preprint arXiv:2402.19473.https://arxiv.org/pdf/2402.19473
[1] Indirect Prompt Injection Into LLMs Using Images and Sounds (Ben Nassi), https://i.blackhat.com/EU-23/Presentations/EU-23-Nassi-IndirectPromptInjection.pdf
[2] As specified on MIT Technology Review:
https://www.technologyreview.com/2024/05/31/1093019/why-are-googles-ai-overviews-results-so-bad/
[i] Training (in AI) - Refers to the process of teaching a machine learning model to learn patterns and relationships from data. During this phase the model adjusts its internal parameters based on examples from a labelled dataset, with the goal of optimizing its performance on a specific task.
[ii] Hallucination (in AI) - In artificial intelligence, hallucinations are instances where an AI model produces factually incorrect or nonsensical information that appears plausible but is not based on reality or the data provided.
[iii] Retriever (in AI) - A type of artificial intelligence designed to retrieve relevant information from a large datasets in response to a user's query. Retrievers are commonly used in search engines, question-answering systems, and recommendation engines.
[iv] Generator (in AI) - In the context of generative models, a ‘generator’ refers to a component or model that produces new data samples. The generator's primary role is to learn and replicate the underlying distribution of the training data, creating new instances that are indistinguishable from the original data.
[v] Transformer (in AI) - A deep learning model architecture that is primarily used for natural language processing (NLP) tasks. It has become a foundational model in the field of NLP, with a wide range of applications including machine translation, text generation, and language understanding.
[vi] Generative models - Class of machine learning models designed to generate new data samples from the same distribution as the training data.